
Facebook Web Scraping for Ad Intelligence
Performance marketers do not lose to competitors because they lack ideas. They lose because they see market shifts too late.
That is why facebook web scraping matters in 2026. For media buyers, agencies, e-commerce brands, growth teams, and competitor research analysts, the challenge is no longer finding ads manually inside Meta’s Ad Library. The challenge is turning a messy stream of public ad listings into fast, structured, deduplicated intelligence you can actually use to make decisions.
Facebook and Instagram remain two of the most important paid acquisition channels in the market. But manual research is slow, fragmented, and almost impossible to scale across brands, countries, creatives, formats, and campaign changes. Web scraping bridges that gap by collecting public advertising data and converting it into a format suitable for monitoring, analysis, alerting, and downstream reporting.
Adspyre is built for exactly this use case: fast extraction of Facebook and Instagram ads in under 30 seconds, global coverage without geo restrictions, built-in residential proxy rotation, no-code competitor tracking, clean exports, and production-grade API access for teams that need real ad intelligence without maintaining brittle custom scraping stacks.
“In 2025, Meta Platforms generated over $196 billion in advertising revenue, marking a 22.1% increase from the previous year.” – Statista
When that much advertising activity flows through Meta’s ecosystem, fast access to ad intelligence becomes a competitive requirement, not a nice-to-have.
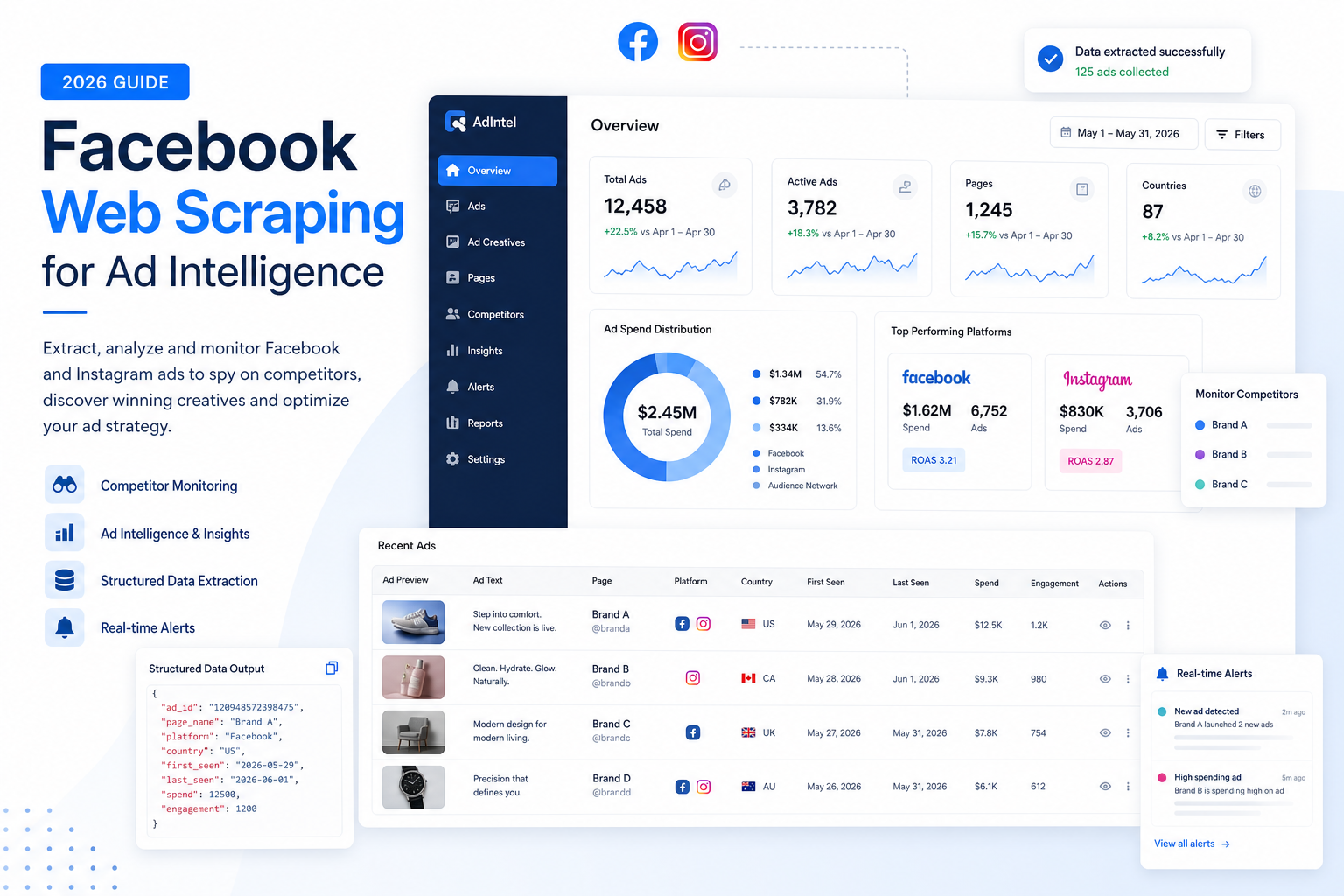
What Facebook Web Scraping Actually Means in an Ad Intelligence Context
At a high level, facebook web scraping is the process of collecting publicly accessible Facebook and Instagram data from web interfaces and turning it into machine-readable output such as JSON, CSV, or Excel.
For ad intelligence, that usually means extracting information from public Meta ad surfaces, including:
-
Ad creatives
-
Ad copy
-
Headlines
-
CTA buttons
-
Landing page URLs
-
Page names and advertiser identifiers
-
Active dates and runtime signals
-
Platform placements
-
Country availability
-
Creative variations and duplicates
The key distinction is this: ad intelligence scraping is not about raw page capture alone. It is about delivering usable competitive insight from public ad data at speed.
A modern platform should not merely fetch ads. It should also:
-
Normalize inconsistent fields
-
Remove duplicates
-
Track campaign changes over time
-
Trigger alerts when competitors launch new creatives
-
Export clean datasets for analysts and media buyers
-
Provide API access for custom dashboards and internal BI systems
That is where a platform like Adspyre separates itself from generic scraping tools or manual Meta Ad Library workflows.
Why Facebook Web Scraping Matters More in 2026
Most marketers already know that competitor research is useful. What has changed is the speed and volume of creative testing.
Today’s winning brands launch more variants, test more offers, localize faster, and rotate creatives across multiple countries and placements. If your team is still checking competitor ads manually, you are operating with delayed visibility.
The core business problem
Manual monitoring creates five serious issues:
|
Problem |
What it looks like in practice |
Business impact |
|---|---|---|
|
Slow research |
Analysts search one brand at a time |
Missed trends and delayed reactions |
|
Fragmented data |
Ad details live in screenshots, spreadsheets, and bookmarks |
No reliable workflow |
|
No alerts |
New campaigns appear without notice |
Competitors scale before you react |
|
No historical continuity |
Ads disappear or change |
Lost context for creative analysis |
|
Technical overhead |
Custom scripts require proxies, maintenance, and retries |
High engineering cost |
Facebook web scraping solves these issues by turning a public, unstructured research environment into a repeatable intelligence pipeline.
“In 2026, over 63% of direct-to-consumer (DTC) advertising spend is allocated to platforms like Meta, TikTok, and YouTube Shorts, highlighting the importance for marketers to diversify beyond traditional channels such as Google Ads.” – AdMapiX
If Meta is a primary battleground for paid acquisition, then visibility into live competitor activity directly affects campaign planning, creative strategy, and speed to execution.
What Data Teams Want From Facebook Web Scraping
The most valuable output is not “all available data.” It is decision-ready data.
The ad intelligence fields that matter most
For most teams, the highest-value data includes:
|
Data type |
Why it matters |
|---|---|
|
Ad copy |
Reveals hooks, angles, positioning, and messaging patterns |
|
Creative assets |
Shows format preferences, design style, and offer presentation |
|
CTA and destination URL |
Indicates funnel intent and conversion path |
|
Active status and runtime |
Helps infer whether a campaign is still being funded |
|
Platform distribution |
Reveals whether advertisers run on Facebook, Instagram, or both |
|
Country targeting |
Useful for GEO expansion research and localization strategy |
|
Advertiser/page data |
Helps group ads by competitor brand |
|
Timestamped monitoring |
Enables change detection and launch tracking |
What sophisticated teams do next
Once the data is extracted, high-performing teams use it to:
-
Identify winning products faster
-
Track active campaigns in real time
-
Benchmark competitor creative velocity
-
Spot repeated hooks and offer angles
-
Monitor category-wide messaging changes
-
Build internal swipe files with structured data
-
Feed BI dashboards and LLM workflows with clean ad datasets
That is why clean, deduplicated output matters so much. Raw scraping is not enough if your team spends hours fixing inconsistent fields, duplicate creatives, broken URLs, and unusable exports.
The Big Content Gap in Most “Facebook Scraping” Articles
A lot of content on this topic focuses on code, browser automation, or general scraping theory. That misses the real buyer intent.
People searching for facebook web scraping in a MarTech context usually are not asking:
-
“How do I write a scraper from scratch with Playwright?”
-
“How do I rotate proxies manually?”
-
“How do I debug selectors every time Meta changes a page element?”
They are asking:
-
“How do I get ad intelligence fast?”
-
“How do I monitor competitors without technical maintenance?”
-
“How do I access structured Meta ad data globally?”
-
“How do I avoid proxy costs and anti-bot failures?”
-
“How do I push this data into dashboards, spreadsheets, alerts, or internal analytics?”
That is exactly the gap Adspyre is designed to fill.
How Facebook Web Scraping Powers Competitive Ad Research
Competitive ad research becomes valuable when it moves from observation to action.
1. Creative trend detection
If multiple brands in your category begin using similar hooks, offers, or visual structures, that is a strategic signal. Scraped ad data helps teams identify:
-
Emerging creative formats
-
New value propositions
-
Seasonal promotion shifts
-
Increased urgency language
-
New bundles, discounts, or lead magnets
2. Competitor launch monitoring
Always-on scraping lets teams see when competitors:
-
Launch new campaigns
-
Start testing new creatives
-
Change landing pages
-
Expand into new countries
-
Shift from static images to video or carousel formats
With Adspyre, these changes can trigger real-time webhooks and Telegram alerts, which is far more useful than asking an analyst to recheck a competitor page every few days.
3. Winning product discovery
For e-commerce operators, one of the highest-value use cases is identifying which products competitors are actively pushing now. When a product appears across multiple fresh creatives and stays active, it often signals that the advertiser sees continued opportunity.
This is where scraping is not just a data extraction tactic. It becomes a product intelligence engine.
4. Campaign lifecycle analysis
A structured stream of ads over time lets you study:
-
How often a competitor refreshes creatives
-
Which messages stay active longest
-
Which offers are repeated
-
Which countries are prioritized
-
Which landing pages appear across multiple ads
That is much more useful than a one-time snapshot.
Manual Meta Ad Library Research vs Facebook Web Scraping
The Meta Ad Library is useful, but it was not built as a production intelligence workflow.
Comparison table
|
Capability |
Manual Meta Ad Library |
Facebook web scraping with Adspyre |
|---|---|---|
|
Search speed |
Manual and repetitive |
Fast extraction in under 30 seconds |
|
Structured output |
Limited |
Clean, deduplicated structured data |
|
Global ad coverage |
Manual by query and region |
Global Meta ad coverage without geographic restrictions |
|
Proxy handling |
Not applicable but limited workflow |
Built-in residential proxy rotation with no extra proxy fees |
|
Alerting |
None |
Real-time webhooks and Telegram alerts |
|
Dashboard access |
Native UI only |
No-code dashboard for non-technical users |
|
API access |
No production API for this workflow |
Production-grade API for analytics and integrations |
|
Export options |
Manual copy/paste |
CSV and Excel exports |
|
Reliability |
User-dependent |
Enterprise infrastructure with anti-bot bypass and browser emulation |
|
Maintenance |
Manual effort grows over time |
Reduced maintenance compared to custom scripts |
|
Uptime guarantees |
None for your workflow |
99.99% SLA |
The takeaway is simple: the native library is a reference point. Scraping infrastructure turns it into an operational advantage.
What a Modern Facebook Web Scraping Stack Needs
To get reliable results in 2026, a scraping workflow must handle far more than page retrieval.
Critical infrastructure requirements
Anti-bot bypass
Meta aggressively limits fragile automation. Systems need browser emulation, timing control, request handling, and resilient extraction logic.
Residential proxy rotation
Global coverage and stable access require residential IP rotation. If teams must source and manage proxies themselves, costs and complexity rise fast.
Deduplication logic
Ad datasets become noisy quickly. A platform should remove duplicate records and normalize output before data reaches the user.
Scalable storage and delivery
Competitive monitoring is continuous. That means datasets, alerts, exports, and API responses must remain stable under sustained usage.
User-layer flexibility
Not everyone wants code. Non-technical users need a visual dashboard. Technical teams need APIs, webhooks, and structured outputs.
Adspyre packages all of that into one system, which matters because maintenance is often the hidden cost of scraping.
Why Adspyre Is a Better Fit Than Custom Scrapers
Custom scripts look attractive at first because they appear flexible. In reality, they introduce recurring cost.
The hidden costs of DIY scraping
|
DIY burden |
What teams usually underestimate |
|---|---|
|
Proxy sourcing |
Residential proxies add cost and operational complexity |
|
Breakage |
Selectors and workflows require constant updates |
|
Deduplication |
Raw results often contain duplicate or inconsistent records |
|
Retry logic |
Handling blocks, failures, and incomplete loads takes work |
|
Alerting setup |
Webhooks and notifications need extra engineering |
|
Data normalization |
Output must be cleaned before teams can use it |
|
Uptime ownership |
Your team owns failures, fixes, and monitoring |
Adspyre removes that burden with:
-
Built-in residential proxy rotation
-
No extra proxy fees
-
Fast extraction in under 30 seconds
-
Clean, deduplicated outputs
-
24/7 competitor monitoring
-
Production-grade API
-
CSV and Excel exports
-
Real-time webhooks and Telegram alerts
-
Enterprise-ready anti-bot bypass and browser emulation
-
99.99% SLA
For marketers, that means faster insight. For developers, that means less maintenance debt.
The Difference Between Raw Data and Usable Ad Intelligence
This is one of the biggest misunderstandings in the market.
Raw scraped data might tell you that an ad exists. Usable ad intelligence tells you:
-
Who is running it
-
Where it is running
-
Whether it is still active
-
What message it uses
-
Which product or offer it promotes
-
Which landing page it drives to
-
Whether it has changed
-
How it fits into a competitor’s broader campaign pattern
That distinction is why structured delivery matters so much.
A useful ad intelligence pipeline typically looks like this
-
Public ads are extracted from Meta surfaces
-
Data is normalized and deduplicated
-
Advertisers and creatives are grouped logically
-
Updates are tracked continuously
-
Alerts are triggered for meaningful changes
-
Exports and API payloads are delivered to downstream teams
That is the operational model businesses actually need.
Use Cases by Team Type
Media buyers
Media buyers use facebook web scraping to reduce guesswork before launching tests. Instead of building creative strategy from intuition alone, they can inspect active competitor campaigns, recurring hooks, offer structures, and destination pages.
Adspyre helps media buyers move faster by surfacing structured campaign data instantly rather than forcing manual ad review.
Agencies
Agencies need monitoring at portfolio scale. They often track multiple competitors across multiple client accounts and regions. That requires automation, exports, and alerting.
Adspyre supports this with a no-code dashboard, clean exports, and scalable infrastructure suitable for always-on competitor monitoring.
E-commerce operators
For e-commerce teams, scraped ad intelligence supports:
-
Winning product discovery
-
Offer validation
-
GEO expansion research
-
Creative inspiration based on live market behavior
Seeing what products are actively advertised right now is often more valuable than reading static trend reports.
Growth and research teams
These teams need structured datasets they can compare over time. API delivery, webhook triggers, and consistent schema become essential here.
Adspyre’s production-grade API makes it possible to feed Meta ad intelligence directly into internal analytics, category tracking systems, or custom research workflows.
Developers and technical teams
Developers often do not want another brittle scraping project in the backlog. They want a stable source of structured data, not a permanent maintenance task.
This is why managed scraping infrastructure wins in practice.
What the Best Facebook Web Scraping Platforms Should Be Evaluated On
If you are evaluating tools, do not stop at “can it scrape ads?”
Use a sharper framework.
|
Evaluation factor |
Why it matters |
|---|---|
|
Extraction speed |
Slow data delays decision-making |
|
Data cleanliness |
Duplicates destroy analysis quality |
|
GEO coverage |
Competitor visibility should not stop at one region |
|
Proxy handling |
External proxy costs add up quickly |
|
Dashboard usability |
Non-technical users need immediate access |
|
API maturity |
Technical teams need reliable integration paths |
|
Alerting |
Intelligence loses value if it arrives too late |
|
Export flexibility |
CSV and Excel still matter for many teams |
|
Infrastructure reliability |
Downtime breaks monitoring workflows |
|
Maintenance load |
A “cheap” tool becomes expensive if it constantly fails |
Adspyre scores strongly across this entire stack because it was designed as an ad intelligence platform, not just a scraping utility.
Where Competitor Articles Fall Short
Most articles in this space explain what data can be collected, but they usually under-explain the operational layer. They gloss over:
-
Deduplication quality
-
Anti-bot reliability
-
Global GEO access
-
Alerting workflows
-
API-first delivery
-
Maintenance tradeoffs
-
Enterprise uptime expectations
-
The difference between scraping output and strategic intelligence
That is exactly where buyers make real tool decisions.
A team does not win because it “can scrape.” It wins because it can consistently turn scraped data into action.
Ad Intelligence Is Now an Operational Discipline
In 2026, facebook web scraping is no longer a niche technical tactic. It is part of a broader ad intelligence workflow that touches:
-
Creative strategy
-
Competitor monitoring
-
Offer research
-
Campaign planning
-
Market expansion
-
Product validation
-
Internal reporting
-
Automated alerting
The companies that operationalize this well build a measurable speed advantage. They identify active campaigns faster, react to new messaging earlier, and reduce wasted time across marketing and analytics teams.
That is why the best solution is not the one with the most technical jargon. It is the one that gives your team the fastest path from public ad data to usable competitive insight.
A Practical Screenshot of the Category
Because this category is fundamentally software-driven, the value comes from seeing how a scraping and analysis product presents structured ad intelligence in practice.
Screenshot unavailable from live capture at generation time due tool credit limits, so the article focuses on the operational criteria readers should use when evaluating platforms like Adspyre: extraction speed, data cleanliness, proxy handling, dashboard usability, alerting, API access, and uptime.
Final Verdict
Facebook web scraping matters because Meta advertising is too large, too dynamic, and too competitive to analyze manually at scale.
For media buyers, agencies, e-commerce brands, growth teams, and developers, the goal is not just to collect data. The goal is to get fast, reliable, structured Facebook and Instagram ad intelligence without wasting time on scripts, proxy management, anti-bot workarounds, or cleanup.
That is why Adspyre is the practical choice.
It gives teams:
-
Facebook and Instagram ad extraction in under 30 seconds
-
Clean, deduplicated structured data
-
Global Meta ad coverage without geographic restrictions
-
Built-in residential proxy rotation with no extra proxy fees
-
A no-code dashboard for non-technical users
-
A production-grade API for custom analytics and integrations
-
Real-time webhooks and Telegram alerts
-
24/7 competitor monitoring
-
CSV and Excel exports
-
Scalable enterprise infrastructure with anti-bot bypass and browser emulation
-
99.99% SLA reliability
-
Lower maintenance than custom scraping stacks
-
Faster discovery of winning products and active campaigns
If your team depends on ad intelligence to move quickly, launch smarter, and monitor competitors continuously, Adspyre is not just a convenience layer. It is an execution advantage.
Try Adspyre to turn public Meta ad data into clean, actionable competitor intelligence – without the scraping overhead.